This project addresses SemEval 2024 Task 8 Subtask A, which involves binary classification of text as either human-written or machine-generated. It leverages transformer-based models—RoBERTa, BART, and GPT-2—and applies parameter-efficient fine-tuning with LoRA to improve classification accuracy and computational efficiency. The system is tested on both familiar and unfamiliar domains using the official SemEval dataset and demonstrates strong generalization across varying text sources and styles.
Notably, RoBERTa fine-tuned with LoRA achieved an F1-score of 0.96 on AI-generated content in the familiar domain, while BART with LoRA performed best in the unfamiliar domain with an F1-score of 0.88, demonstrating strong generalization and adaptability across varying contexts.

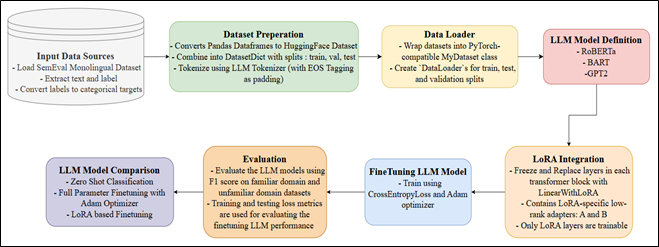
- Binary classification of text (Human vs AI-generated)
- Zero-shot evaluation using RoBERTa, BART, GPT-2, and GPT-4o
- Parameter-efficient fine-tuning using LoRA
- Performance analysis across familiar and unfamiliar domains
- Balanced training using undersampling and structured preprocessing
- Domain generalization evaluation on OUTFOX dataset and GPT-4 generated content
- Results for the models using Adam Optimizer:
- Results for the models using LoRA:


The dataset used for this project is the official SemEval 2024 Task 8 Subtask A Monolingual dataset: https://drive.google.com/drive/folders/1CAbb3DjrOPBNm0ozVBfhvrEh9P9rAppc
- Language: Python 3.9+
- Frameworks & Libraries:
- PyTorch
- Hugging Face Transformers
- PEFT (Parameter-Efficient Fine-Tuning)
- Datasets (Hugging Face)
- scikit-learn
- Accelerate
- Platform: Google Colab Pro (with T4, L4, and A100 GPUs)
- Hardware Requirements:
- Minimum 16 GB RAM
- 5 GB disk space
- At least 16 GB GPU memory for LoRA-based fine-tuning
The models can be tested using historical Bitcoin price data to verify prediction accuracy.